凯发·k8国际娱乐网从 30 秒稳健阐释勾股定理-凯发k8首页「中国」官方网站登录入口
 凯发·k8国际娱乐网
凯发·k8国际娱乐网
赶在休假前,支棱起来的国产 AI 大模子厂商井喷式发布了一大堆春节礼物。
前脚 DeepSeek-R1 安定发布,堪称性能对标 OpenAI o1 郑再版,后脚 k1.5 新模子也安定登场,示意性能作念到满血版多模态 o1 水平。

如若再加上此前强势登场的智谱 GLM-Zero,阶跃星辰推理模子 Step R-mini,星火深度推理模子 X1,年末上大分的国产大模子拉开了真刀真枪的帷幕,也予以 OpenAI 为代表的国际模子狠狠上了一波压力。
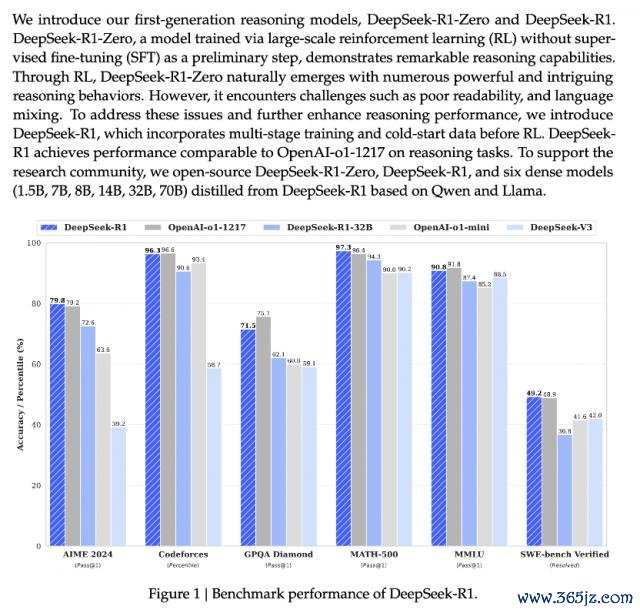
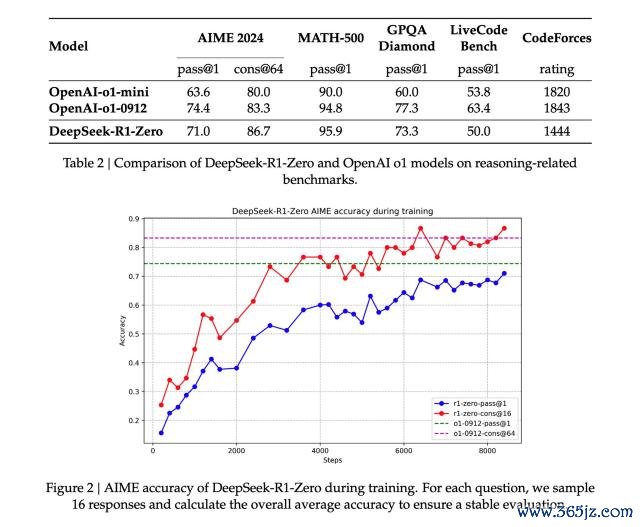
DeepSeek-R1 :在数学、代码、当然话语推理等任务上,性能并列 OpenAI o1 郑再版
月之暗面 k1.5:数学、代码、视觉多模态和通用才能全面越过 GPT-4o 和 Claude 3.5 Sonnet。
智谱 GLM-Zero:擅所长理数理逻辑、代码和需要深度推理的复杂问题
阶跃 Step-2 mini:极速反馈,平均首字时延仅 0.17 秒,还有 Step-2 文豪版
星火 X1:数学才能亮眼,有全面念念考经过,拿捏小学、初中、高中、大学全学段数学
井喷不是有时的爆发,而是蕴蓄已久的力量,不错说,国产 AI 模子在春节前夜的解围,将有望再行界说 AI 发展的全国坐标。
中国版「源神」爆火国际,这才是真 · OpenAI
昨晚率先发布的 DeepSeek-R1 咫尺仍是上架 DeepSeek 官网与 App,盛开就能用。
9.8 和 9.11 哪个大以及 Strawberry 里有几个 r 的贫困在第一次测试中就顺利过关,别看念念维链略显冗长,但正确谜底事实胜于雄辩。
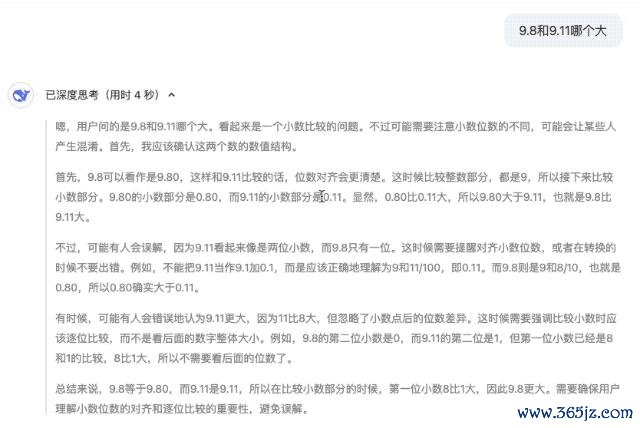
面对弱智吧贫困「跳多高才能跳过手机上的告白」的拷问, 反馈速率极快的 DeepSeek-R1 不仅能够消亡话语陷坑,还提供了不少隐敝告白的的建议,非凡东谈主性化。

几年前,有一齐名为「如若昨天是未来,今天便是星期五,内容今天是星期几」的逻辑推理题走红集合,在面对同样问题的拷问后,OpenAI o1 给出的谜底是周日,DeepSeek-R1 则是周三。
但就咫尺来看,至少 DeepSeek-R1 更连合谜底。

据先容,DeepSeek-R1 在数学、代码、当然话语推理等任务上,性能并列 OpenAI o1 郑再版,表面上更偏向于理科生。
偶合赶上小红书上中好意思两国网友在友好同样数学功课,咱们也让 DeepSeek-R1 赞通晓疑答惑。
插个冷学问,上回 DeepSeek 国际爆火时就有网友发现,其实 DeepSeek 也救援图片识别,咱们不错径直让模子分析好意思国网友上传的试卷图片。
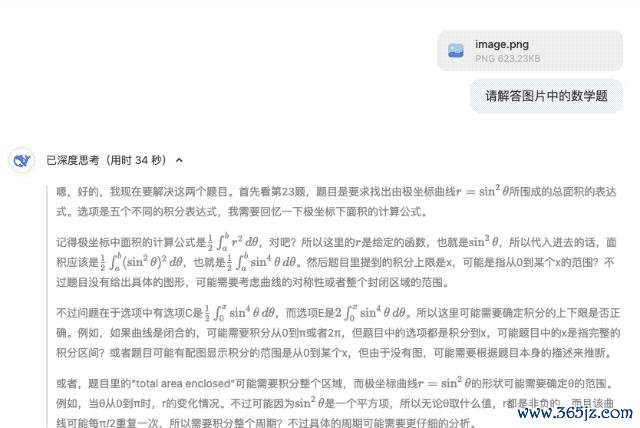
拢共两谈题,第一齐题选 C,第二谈题选 A,何况,「自信满满」的 DeepSeek-R1 推测第二谈题原题的选项中无 18,衔尾选项推测原题可能存在笔误(如方程应为 r2=9cos ( 2 θ ) r2=9cos ( 2 θ ) )。
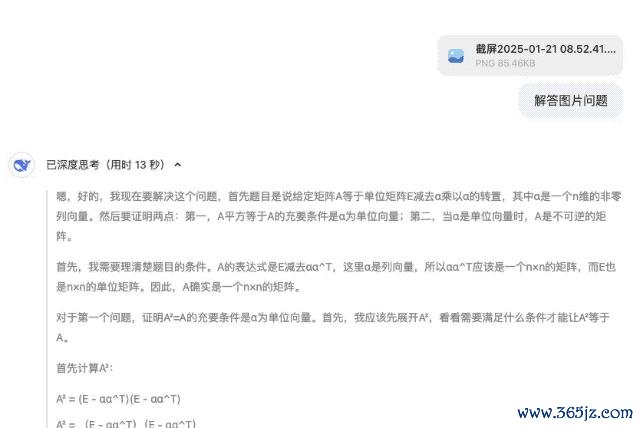
在随后的线性代数讲明题中,,DeepSeek-R1 提供的讲明设施逻辑严谨,团结齐题目还提供了多种考据步履,展现出深厚的数学功底。
始于性能,陷于资本,忠于开源。 DeepSeek-R1 安定发布之后,也同步开源模子权重。我文告,来自中国东方的 DeepSeek 才是信得过的 OpenAI。
据悉,DeepSeek-R1 衔命 MIT License,允许用户通过蒸馏时刻借助 R1 磨真金不怕火其他模子。DeepSeek-R1 上线 API,对用户开放念念维链输出,通过建立 model='deepseek-reasoner' 即可调用。
何况,DeepSeek-R1 磨真金不怕火时刻全部公开,论文相接指路� � https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
DeepSeek-R1 时刻诠释里提到一个值得温雅的发现,那便是 R1 zero 磨真金不怕火经过里出现的「aha moment(顿悟时刻)」。
在模子的中期磨真金不怕火阶段,DeepSeek-R1-Zero 脱手主动再行评估开动解题念念路,并分拨更多时辰优化计谋(如屡次尝试不同解法)。换句话说,通过 RL 框架,AI 可能自愿酿成类东谈主推理才能,以致越过预设划定的限度。
何况这也将有望为斥地更自主、自得当的 AI 模子提供标的,比如在复杂有计划(医疗会诊、算法想象)中动态调整计谋。正如诠释所说,「这一时刻不仅是模子的『顿悟时刻』,亦然谈判东谈主员不雅察其手脚时的『顿悟时刻』。」

除了主打的大模子,DeepSeek 的小模子同样实力不俗。
DeepSeek 通过对 DeepSeek-R1-Zero 和 DeepSeek-R1 这两个 660B 模子的蒸馏,开源了 6 个小模子。其中,32B 和 70B 型号在多个畛域达到了 OpenAI o1-mini 的水准。
何况,仅 1.5B 参数大小的 DeepSeek-R1-Distill-Qwen-1.5B 在数学基准测试中越过了 GPT-4o 和 Claude-3.5-Sonnet,AIME 得分为 28.9%,MATH 得分为 83.9%。
HuggingFace 相接:https://huggingface.co/deepseek-ai
在 API 服务订价方面,堪称 AI 届拼多多的 DeepSeek 也接纳了机动的门路订价:每百万输入 tokens 证明缓存情况收费 1-4 元,输出 tokens 长入 16 元,再次大幅镌汰斥地使用资本。
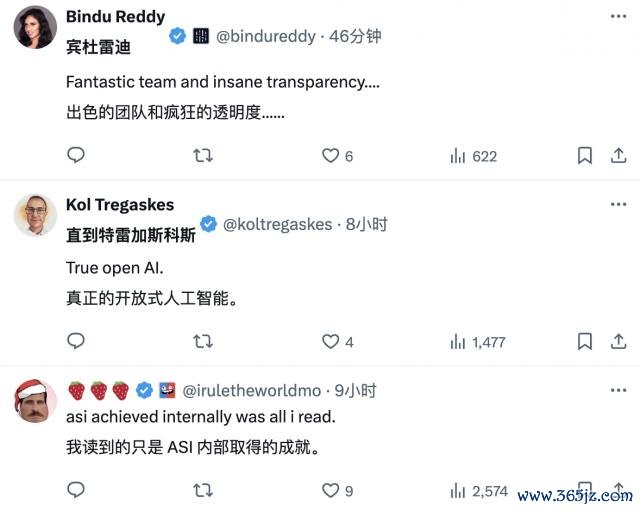
DeepSeek-R1 发布以后,也再次在国际 AI 圈引起震荡,收货了无数「自来水」。其中,博主 Bindu Reddy 更是给 Deepseek 冠上了开源 AGI 和娴雅的来日之称。

出色的评价源于模子在网友的内容欺诈中出色的推崇。从 30 秒稳健阐释勾股定理,到 9 分钟深刻浅出地汲引量子电能源学旨趣并提供可视化呈现。DeepSeek-R1 莫得任何盘曲。
https://x.com/christiancooper/status/1881343268916748480
以致也有网友非凡观赏 DeepSeek-R1 所展示的念念维链,觉得「像极了东谈主类的内心独白,既专科又可人」。
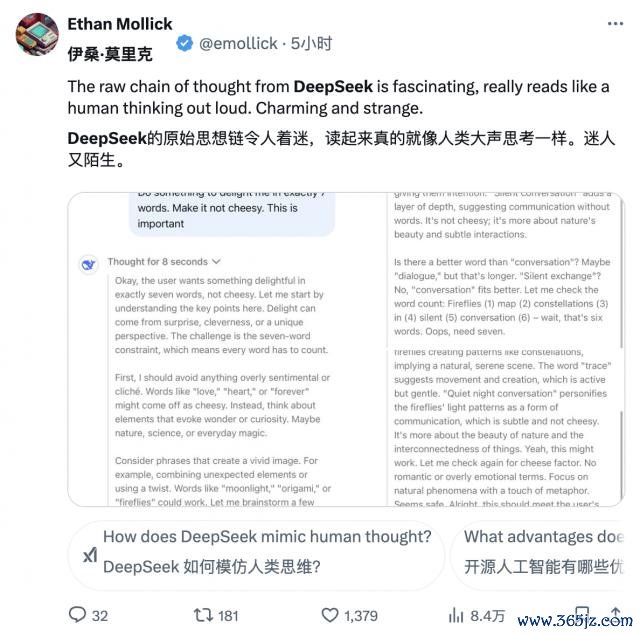
英伟达高等谈判科学家 Jim Fan 对 DeepSeek-R1 给予了高度评价。他指出这代表着非好意思国公司正在践行 OpenAI 伊始的开放职责,通过公开原始算法和学习弧线等格式已矣影响力,趁便还内涵了一波 OpenAI。
DeepSeek-R1 不仅开源了一系列模子,还败露了所有磨真金不怕火精巧。它们可能是首个展示 RL 飞轮首要且络续增长的开源技俩。
影响力既不错通过『ASI 里面已矣』或『草莓倡导』等听说般的技俩已矣,也不错肤浅地通过公开原始算法和 matplotlib 学习弧线来达成。
在深刻谈判论文后,Jim Fan 非凡强调了几个要道发现:
透顶由强化学习驱动,莫得任何 SFT(「冷启动」)。让东谈主逸猜度 AlphaZero ——从零脱手掌捏围棋、将棋和国际象棋,而不是先师法东谈主类内行的棋步。这是论文中最要道的发现。 使用硬编码划定推断果泄漏奖励。
幸免使用强化学习容易破解的学习奖励模子。 跟着磨真金不怕火进展,模子的念念考时辰冉冉增多——这不是事前编写的标准,而是一种袒露性情! 自我反念念和探索手脚的袒露。
GRPO 替代了 PPO:它移除了 PPO 的驳倒集合,改用多个样本的平均奖励。这是一种减少内存使用的肤浅步履。需要堤防的是,GRPO 是作家团队提议的一种翻新步履。
合座来看,这项劳动展示了强化学习在大畛域场景中内容欺诈的草创性后劲,并讲明某些复杂手脚不错通过更肤浅的算法结构已矣,而无需进行繁琐的调整或东谈主工侵扰。
一图胜千言,更彰着的对比如下:
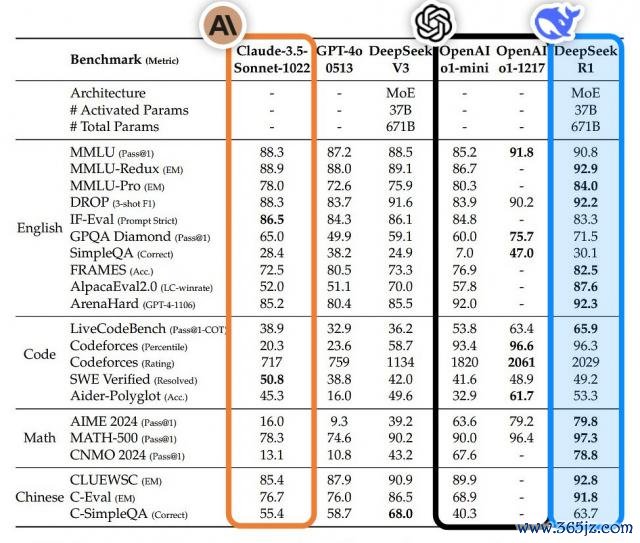
就这么,DeepSeek 再次在海表里完成二次爆火,不仅是一次时刻破损,更是中国乃至全国的开源精神的奏效,也因此收货了不少国际至意拥趸。
新模子并列 OpenAI o1,三个月三次破损,Kimi 让国际集体本旨
团结天上线的还有 Kimi v1.5 多模态念念考模子。
自客岁 11 月 Kimi 推出 k0-math 数学模子,12 月发布 k1 视觉念念考模子以来,这是第三次 K 系列的进攻上新。
在短念念考模式(short-CoT)的较量中,Kimi k1.5 展现出压倒性上风,其数学、代码、视觉多模态和通用才能全面越过了行业翘楚 GPT-4o 和 Claude 3.5 Sonnet。
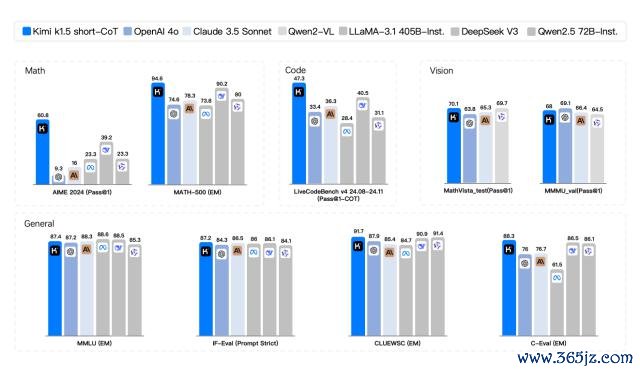
在长念念考模式(long-CoT)的竞争中,Kimi k1.5 的代码和多模态推理才能仍是并列 OpenAI o1 郑再版,成为寰球范围内首个在 OpenAI 除外已矣 o1 级别多模态推感性能的模子。
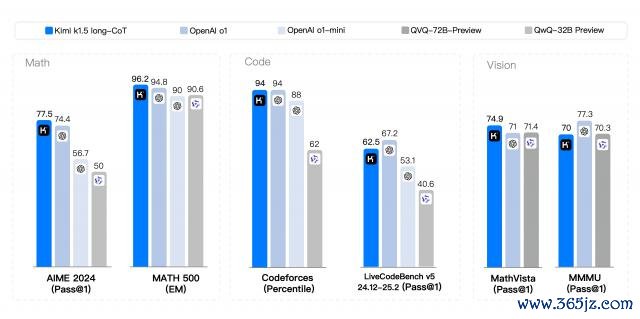
伴跟着模子的重磅发布,Kimi 还初度公开了完好的模子磨真金不怕火时刻诠释。
GitHub 相接:https://github.com/MoonshotAI/kimi-k1.5
据官方先容,k1.5 模子的中枢时刻破损主要体咫尺四个要道维度:
长高下文推广。咱们将 RL 的高下文窗口推广到 128k,并不雅察到跟着高下文长度的增多,性能络续擢升。咱们的步履背后的一个要道念念想是,使用部分伸开(partial rollouts)来提高磨真金不怕火遵循——即通过重用无数先前的轨迹来采样新的轨迹,幸免了从新脱手再行生成新轨迹的资本。咱们的不雅察标明,高下文长度是通过 LLMs 络续推广 RL 的一个要道维度。
矫正的计谋优化。咱们推导出了 long-CoT 的 RL 公式,并接纳在线镜像下落的变体进行稳健的计谋优化。该算法通过咱们的有用采样计谋、长度搞定和数据配方的优化进一步获取矫正。
粗略的框架。长高下文推广与矫正的计谋优化步履相衔尾,为通过 LLMs 学习建立了一个粗略的 RL 框架。由于咱们能够推广高下文长度,学习到的 CoTs 推崇出缱绻、反念念和修正的性情。增多高下文长度的恶果是增多了搜索设施的数目。因此,咱们展示了不错在不依赖更复杂时刻(如蒙特卡洛树搜索、价值函数和经过奖励模子)的情况下已矣坚贞的性能。
多模态才能。咱们的模子在文本和视觉数据上合伙磨真金不怕火,具有合伙推理两种模态的才能。该模子数学才能出众,但由于主要救援 LaTeX 等形势的文本输入,依赖图形领会才能的部分几何图形题则难以应酬。
k1.5 多模态念念考模子的预览版将连接灰度上线官网和官方 App。值得一提的是,k1.5 的发布同样在国际引起了高大的反响。有网友对这个模子不惜赞叹之词,让国际见证了中国 AI 实力的崛起。
内容上,年末国内推理模子的密集发布绝非有时,这是 OpenAI 客岁 10 月发布 o1 模子在寰球 AI 畛域掀翻的荡漾终于传导至中国的权贵象征。短短数月从追逐到并列,国产大模子用行动讲明了中国速率。
菲尔兹奖得主、数学天才陶哲轩曾觉得这类推理模子能够只需再经过一两轮迭代与才能擢升,就能达到「及格谈判生」的水准。而 AI 发展的前程远不啻于此。

刻下,咱们正见证着 AI 智能体一个要道的转型时刻。从单纯的「学问增强」向「扩充增强」越过,脱手主动参与有计划制定和任务扩充的经过。与此同期,AI 也在破损单一模态的限度,向着多模态和会的标的快速演进。当扩充遇上念念考,AI 才信得过具备了改换全国的力量。
基于此,像东谈主一样念念考的模子正在为 AI 的内容落地开辟更多可能性。
名义上看,年末这波国内推理模子的密集袒露,名义上看能够带有「中国式随从者翻新」的影子,但深刻不雅察就会发现凯发·k8国际娱乐网,不管是在开源计谋的深度,照旧在时刻细节的精准度上,中国厂商依然走出了一条独具特质的发展谈路。